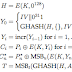Para esta semana se buscaron papers sobre el tema de Redes Sensoras
para la clase de Redes de la Telecomunicación, el paper que encontre
se llama
The Deployment of a Smart Monitoring System using Wireless
Sensors and Actuators Networks
Nicola Bressan, Leonardo Bazzaco, Nicola Bui, et al.
Lo que proponían en este paper es una implementación de un sistema de
vigilancia inteligente en una red de sensores inalámbricos, en donde
se enfocan en un protoloco de enrutamiento sólido a tráves de un protocolo de
enrutamiento que es de bajo costo de energía y con poco ruidos (RPL).
Su estructura se basa en una aplicación ligera de transferencia de
estado de representación (REST) paradigma por medio de un servicio web
binario, y en un mecanismo de publicación y suscripción, por lo que
cada nodo tiene un conjunto de recursos (por ejemplo, sensores
ambientales) a disposición de las partes interesadas.
Realizaron pruebas dentro de una red que se encuentra en prueba dentro
de algunas regiones de Estados Unidos esta red se llama WSAN ahí
buscan modelar el comportamiento de un tamaño de construcción de redes
inteligentes y se centran en la comprensión de si las soluciones
estándar WSAN están preparados para soportar los requerimientos de las
redes inteligentes, las redes sensoras se pueden beneficiar en gran
medida si con usados como los servicios web y que si se utilizan
ampliamente podría tener éxito en mecanismos de integración de algunos
sistemas que permite crear una mayor distribución en cualquier sistema
que sea construido en componentes estándar en cualquier sistema, por
ejemplo en la industria, casa de automatización, así como sistemas de
gestión de energía entre muchas cosas.
TinyREST implementa de una manera eficiente servicios web dentro de la
red WSAN al minimiazar cuidadosamente la sobrecarga introducida por la
capa de transporte, usando formato de datos como XML y WSDL. Los
servicios web se pueden clasificar en base RESTful y base SOAP, aunque
el enfoque le quieren hacer es a RESTful ya que es ligero.
Demostraron la viabilidad de WSAN basada en IP, donde los nodos envían
datos a tráves de servicios web. Este trabajo parte de la
implementación ligera de los servicios web basados en REST en la
arquitectura WSAN.
Hicieron algunos experimentos sobre el enrutamiento, en particular en
la focalización sobre la fase de configuración y las principales
funciones de control como son los parámetros de la función de
configuración del algorítmo RPL. El experimento lo realizaron en la
universidad de Pandova.

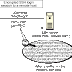
En el despliegue del servidor central se mantiene la conexión a un
nodo que es un sensor que esta colocado en la esquina superior
izquierda de la imagen. La topología de la red se encuentra con 80
nodos de los cuales se han escogido de diferentes area y diferentes
densidades de nodo; lugares como cuellos de botella (pasillos), así
como salas de laboratorio y esto permite probar el rendimiento de
enruteamiento en un entorno de reproducción de un despliegue de redes
inteligentes realista. Cada nodo ejecuta ejecuta el protocolo RPL.
Con el fin de probar el impacto de los parámetros de RPL en la
creación de la infraestructura de enruteamiento dejaron que las
constantes varien un poco en cambios en un tiempo de intervalos
preconfigurados.
Ahora veamos la evaluación de desempeño en donde se muestran los nodos
registrados en tiempo en donde K representa el número de transmisiones
realizadas con el servidor central.
 Conclusión
Conclusión Este trabajo tiene un gran futuro como para cuidades inteligentes, por
medio de este tipo de comunicación podríamos llegar a obtener
servicios de la web sin necesidad de estar conectados en la web esto
ayudaría a que cualquier tipo de lugar inteligente pueda mantener
comunicación con sus actuadores y que así envie información en tiempo
real sin la necesidad de comprar componentes que son relativamente
caros.
ReferenciasNicola Bressan, Leonardo Bazzaco, Nicola Bui, et al. (2013) The Deployment of a Smart Monitoring
System using Wireless Sensors and Actuators Networks.
Disponible en :
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5622015
[Acesado en: 27 Mayo 2013].