




5.3.1. (a)Answer: First we need to make a tree to represent the data provided, next we get the expected value of the original word length and the huffman word length, then we divide the original word length and huffman word length and we get the compression ratio.

To explain my answer I use a good tool online in this page http://huffmandemo.appspot.com/ that's made by Cecilia Urbina.
First I made a Huffman's tree in a notebook by handmade, next I produce a table with the data provided in the problem vs the coded data. To get a length of the word we get the LCM (Least Common Multiple) of the frequency, then we demuestrate using a word with that length. Once we got the information with the word we can get the expected value using the next formulas.

 The first one is for expected value of the coded value (that value that's made with the huffman's tree) and the original that's the word provided in the problem.
The first one is for expected value of the coded value (that value that's made with the huffman's tree) and the original that's the word provided in the problem.
Huffman's Tree.

Table.

Then we do the same procedure in the problem (b).
Huffman's Tree.

Table.

Source:
Introduction to Information Theory and Data Compression by Hankerson et al.




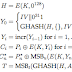



Bien; 3+3 extra en teoría de info. Se dice "following equations" en lugar de "next formulas".
ResponderEliminar