Se eligió un paper sobre el consumo eficiente de energía en el area de
redes de la telecomunicación para realizar un resumen de el, y a continuación
veremos el tema y los autores:
An Energy Efficient Routing Mechanism for Wireless Sensor Networks
by Ruay-Shiung Chang and Chia-Jou Kuo
Ahora hablaremos de lo que se habla en este paper. Se habla sobre la
propuesta de un nuevo protocolo de ruteo llamado
MECH (Maximum Energy
Cluster Head) en el que tiene como propiedades autoconfiguración y
árbol jerarquico de ruteo, y en este protocolo que proponen se tiene
una gran ventaja en comparación con una existen que trata de
solucionar la misma problematica, se llama
LEACH (Low Energy Adaptive
Clustering Hierarchy) en el que dicho protocolo esta basado clustering
en el cual los nodos no usados como cabezas del cluster son apagados
sus RF hasta un tiempo preajustado de tiempo, sin embargo tiene un
inconveniente de que el clúster no se distribuye de manera uniforme
debido a su rotación aleatoria de sus cabezas.
El enfoque principal del protocolo de ruteo esta dividido en rondas y
cada ronda consiste de
3 fases:
fase de establecimiento, fase estable
y fase de expedición. Por cada ronda se crean clusters.
Inicialización de un cluster. Cada nodo hace una emisión a sus vecinos
con un mensaje de hola, el TTL de el mensaje hola se coloca en uno
cuando solamente se necesita reunir a los vecinos de una llamada.
El rango del radio de transmisión se coloca, en el cual esto hace que el
comportamiento de los clusters se limite. Cada nodo guarda el número
de sus vecinos. Se define un parámetro del sistema llamado
número de
clúster (CN). Cuando el número de vecinos de un nodo alcanza el valor
dado CN, el nodo irá a difundir el mensaje "publicitario" a sus vecinos
principales. El anuncio es informar a todos los nodos que "yo soy una
cabeza del cluster".
Todos los nodos que reciban el mensaje "publicitario", lo guardan y comenzarán a
iniciar un temporizador de interrupción. Además, dichos nodos no emiten la
"publicidad", incluso si su número de vecinos alcanza al CN. Esto se debe a
que se establece que solamente hay una sola cabeza en el cluster en un cierto radio.
Después del tiempo de interrupción, cada nodo selecciona una cabeza en
el cluster acorde a la intensidad de la señal y envía devuelta un
mensaje a su cabeza en el cluster. Después de hacer eso, casa cabeza
en el cluster sabra su miembro en el cluster. Para sincronizar la
transmisión en la fase estable se necesita una proporción al número de
miembros del cluster. Para hacer la sincronización cada cabeza del
cluster cuenta el total de número de sus miembreos en el cluster y
cada transmisión de información a su estación base. La estación base
calcula el número máximo de intervalos de tiempo necesitados para
transmitir esta información a cada cabeza de cluster. Como se puede
apreciar en la parte de abajo las 3 fases de las que se hablan.
Url referencia:
Fase de establecimiento. Porque el máximo número de miembros del
cluster es limitado por CN, la cabeza del cluster puede programar el
intervalo de tiempo TDMA para cada miembro del clúster en cada ronda.
Cada nodo se convertirá en el receptor, luego la cabeza del clúster
transmitirá un mensaje que contiene la información del intervalo de
tiempo del TDMA. Cada miembro del clúster mantendrá el transceptor
hasta que el intervalo de tiempo establecido. Además, también
transmite el valor de la energía restante. La cabeza del clúster
mantiene una tabla de cuales nodos tiene la máxima energía en la ronda
actual. Después de que se reenvía los datos de la estación base, se
selecciona un nodo que tiene el máximo poder y se coloca como la
cabeza del clúster en la siguiente ronda.
En la siguiente ronda en la misma fase, se transmitirá información
que contiene la nueva cabeza del clúster en la ronda actual.
Fase estable. Una vez que los clústers son creados y el TDMA se ha
programado, la transmisión de datos puede comenzar. Asumiendo que los
nodos siempre tienen datos a transmititr, ellos envían sus datos y
energía durante el intervalo de tiempo asignado a la cabeza del
clúster. Los nodos del clúster ajustan sus transmisión de energía de
manera dinámica dependiendo de la intensidad de la señal de las
transmisiones de la cabeza del clúster.
En la fase estable solamente la cabeza del clúster siempre estará como
transceptor. Los miembros del clúster solamente estarán como receptores
durante el intervalo de tiempo asignado.
Fase de expedición. MECH usa dos parámetros para establecer la
jerárquia que existe en relación en los clústers:
hop_count (cuenta de
saltos) y
energy level (el nivel de energía). Los pasos siguientes
describen como el MEC implementa la jerárquia.
Paso 1: La estación base transmite un mensaje de hola periodicamente.
El mensaje contiene 2 tipos de información: una es el hop_count desde
la estación base hacía la cabeza del clúster y el otro es el energy
level. El
hop_count es asignado a
0 y el
energy level es colocado de
manera inicial como
infinito. Todo miembro del clústes que no sea la
cabeza ignora el mensaje. Cuando el mensaje se recibe, la cabeza del
clúster agrega un uno al contador de hop_count y lo compara con el
energy level en el mensaje, sí la cabeza del clúster actual esta más
abajo de energía el energy level es remplazado con aquel cabeza del
clúster actual.
Paso 2: Después de que la cabeza del clúster reciba el mensaje de
hola, la cabeza del clúster guardará la cabeza que transmite el
mensaje de hola. Por lo tanto, la cabeza del clúster que transmite
se convertirá en el reenvío de la cabeza del clúster a la estación
base para la cabeza de este clúster. Este mecanismo es similar a la
de un enrutamiento a distancia de vectores.
Paso 3: Sí la cabeza del clúster recibe algún mensaje de hola, este
hara decisiones acorde a las siguientes reglas:
Case 1: Sí hop_count_old < hop_count_new, no hacer nada;
Case 2: Sí hop_count_old > hop_count_new, reemplazar el reenvío a
la cabeza del clúster;
Case 3: hop_count_old = hop_count_new, entonces Sí energy_old >
energy_new entonces se reemplaza la cabeza del clúster; Si no no
sé hace nada;
Las características principales del MECH son las siguientes:
- Reducen la disipación de energía.
- Auto-configuración y coordinación.
- Cabeza del clúster tiene su máxima energía.
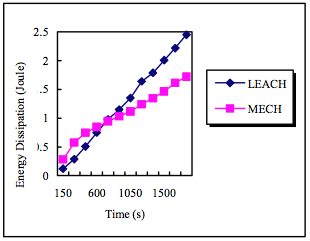
A continuación vemos el rendimiento que tiene MECH vs LEACH, se muestran
como disipan la energía con 10, 15 y 20 clústers.
10 clústers
Url referencia:
15 clústers
Url referencia:
20 clústers
Referencia:


















































{kind=link}